
I am a Master’s student in Applied Math at Fudan University and an incoming CS Ph.D. student at Yale University, advised by Prof. Rex Ying. My current research focuses on Multimodal Structured Reasoning, aiming to build systems that integrate explicit structural priors with dynamic reasoning capabilities. Currently, I am exploring multimodal code generation, post-training strategies for Vision-Language Models (VLMs), and modeling structured reasoning processes. Feel free to reach out if you’d like to learn more about my work, chat, or explore potential collaborations. You can find my publications on my google scholar.
🔥 News
- 2026.05: BMC accepted to ICML 2026.
- 2026.03: Two papers (MacTok and GIFT) accepted to CVPR 2026.
- 2026.02: Joined Microsoft Research Asia (MSRA) as a Research Intern.
- 2026.02: Two papers (ARTDECO and IVQ) accepted to ICLR 2026.
- 2025.09: Two papers (GOOD and OrderMind) accepted to NeurIPS 2025.
- 2025.09: Loong accepted to NeurIPS 2025 Workshop.
- 2025.06: Dark-ISP accepted to ICCV 2025.
- 2025.05: Joined Shanghai AILab as a Research Intern, working with Jie Fu.
- 2025.04: Welcomed two cats into my life: Fellow and Putao 🐱🍇
- 2025.01: MVP accepted to ICLR 2025.
- 2024.12: Joined as a Research Intern, working with Prof. Chenyang Si and Prof. Ziwei Liu.
📝 Selected Publications
My current research interests primarily revolve around Multimodal Structured Reasoning. While I have explored a diverse range of directions in the past—from continuous visual generation to physical scene understanding—these endeavors have ultimately converged on a unified goal: solving the core challenges of multimodal alignment, abstraction, and complex reasoning.
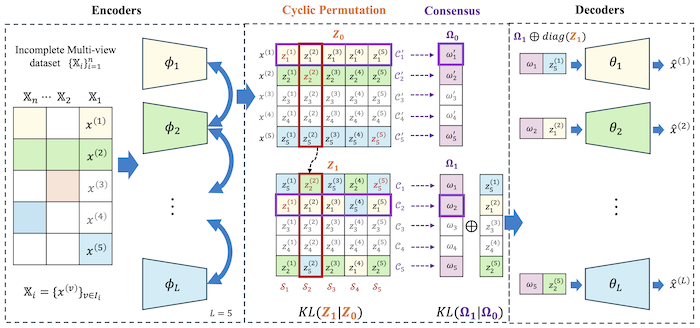
MVP: Deep Incomplete Multi-view Learning via Cyclic Permutation of VAEs
Xin Gao, Jian Pu


- MVP introduces a robust generative approach to incomplete multi-view representation learning by leveraging latent space correspondences in Variational Auto-Encoders. This enables the inference of missing modalities and enhances multi-view consistency even with irregularly missing information.

MacTok: Robust Continuous Tokenization for Image Generation
Hengyu Zeng#, Xin Gao#, Guanghao Li, Yuxiang Yan, Jiaoyang Ruan, Junpeng Ma, Haoyu Albert Wang, Jian Pu
- MacTok addresses the severe “posterior collapse” failure in continuous image tokenizers. By introducing DINO-guided semantic masking and multi-level representation alignment, it forces the model to infer robust semantics from incomplete visual evidence, yielding state-of-the-art generation fidelity.
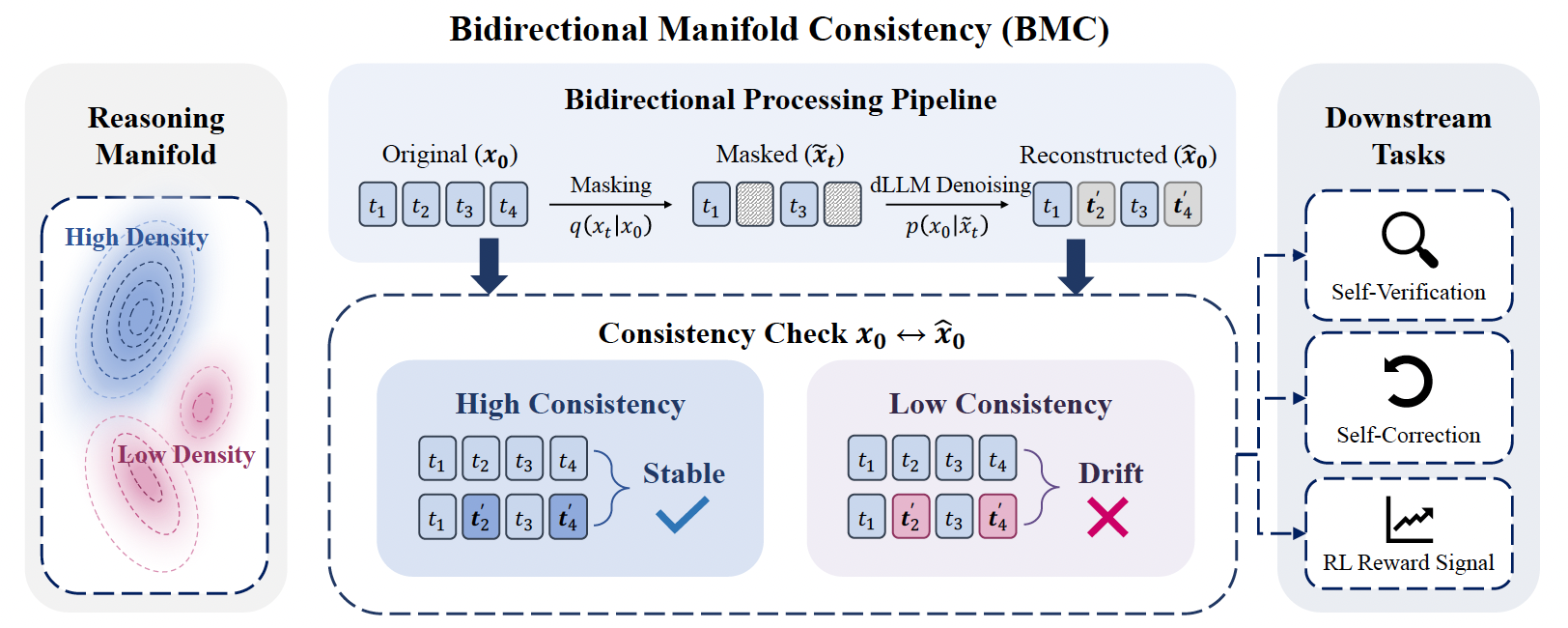
Jiaoyang Ruan#, Xin Gao#, Yinda Chen, Hengyu Zeng, Liang Du, Guanghao Li, Jie Fu, Jian Pu
- BMC introduces a geometric perspective to reasoning in Diffusion Language Models. By framing verifiable trajectories as stable paths on a high-density manifold, it provides an unsupervised mechanism for logical self-verification, empowering models to dynamically verify generation steps and self-evolve.
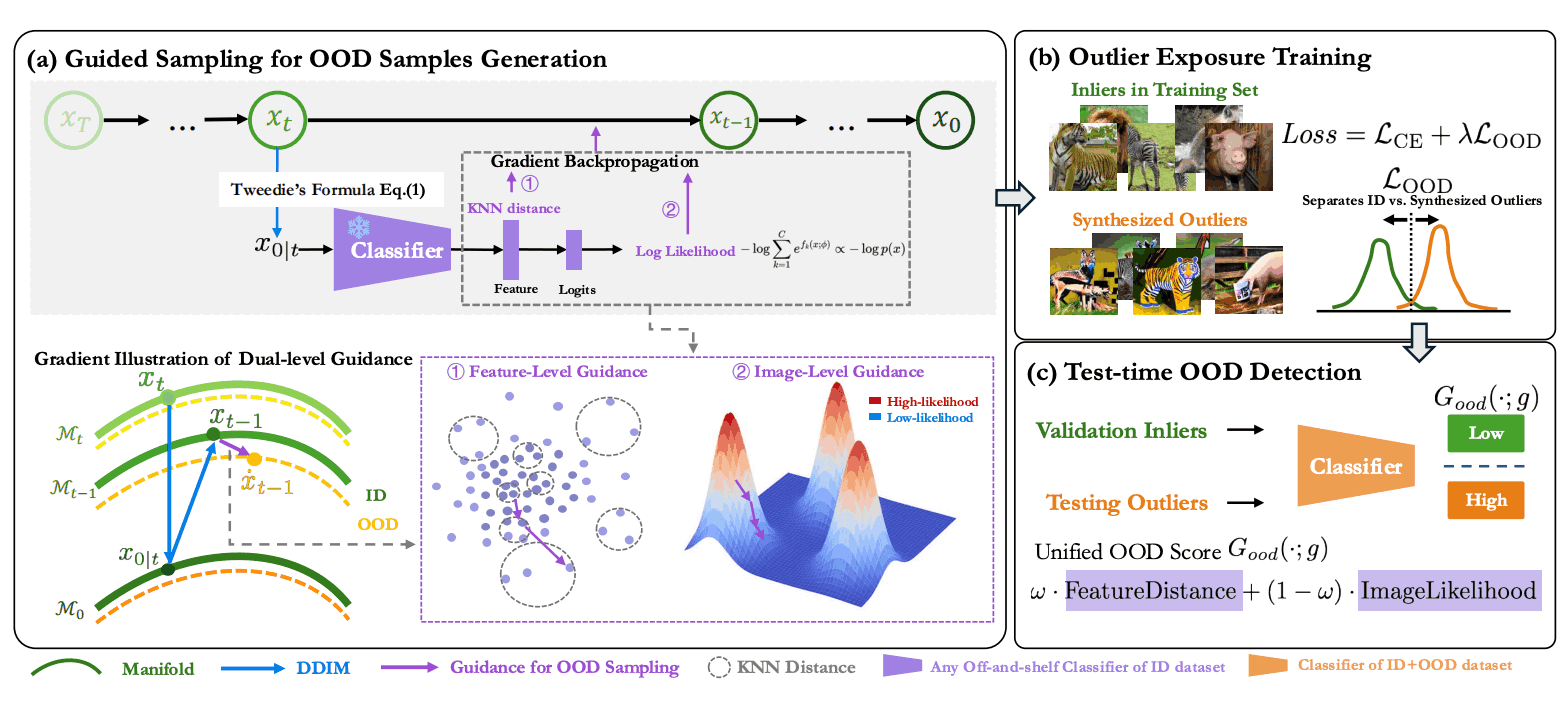
GOOD: Training-Free Guided Diffusion Sampling for Out-of-Distribution Detection
Xin Gao, Jiyao Liu, Guanghao Li, Yueming Lyu, Jianxiong Gao, Weichen Yu, Ningsheng Xu, Liang Wang, Caifeng Shan, Ziwei Liu, Chenyang Si
- GOOD is a training-free diffusion guidance framework that shapes a robust OOD/ID classification boundary. It steers sampling with image-level and feature-level gradients to systematically generate diverse, controllable OOD examples for robust decision-making.
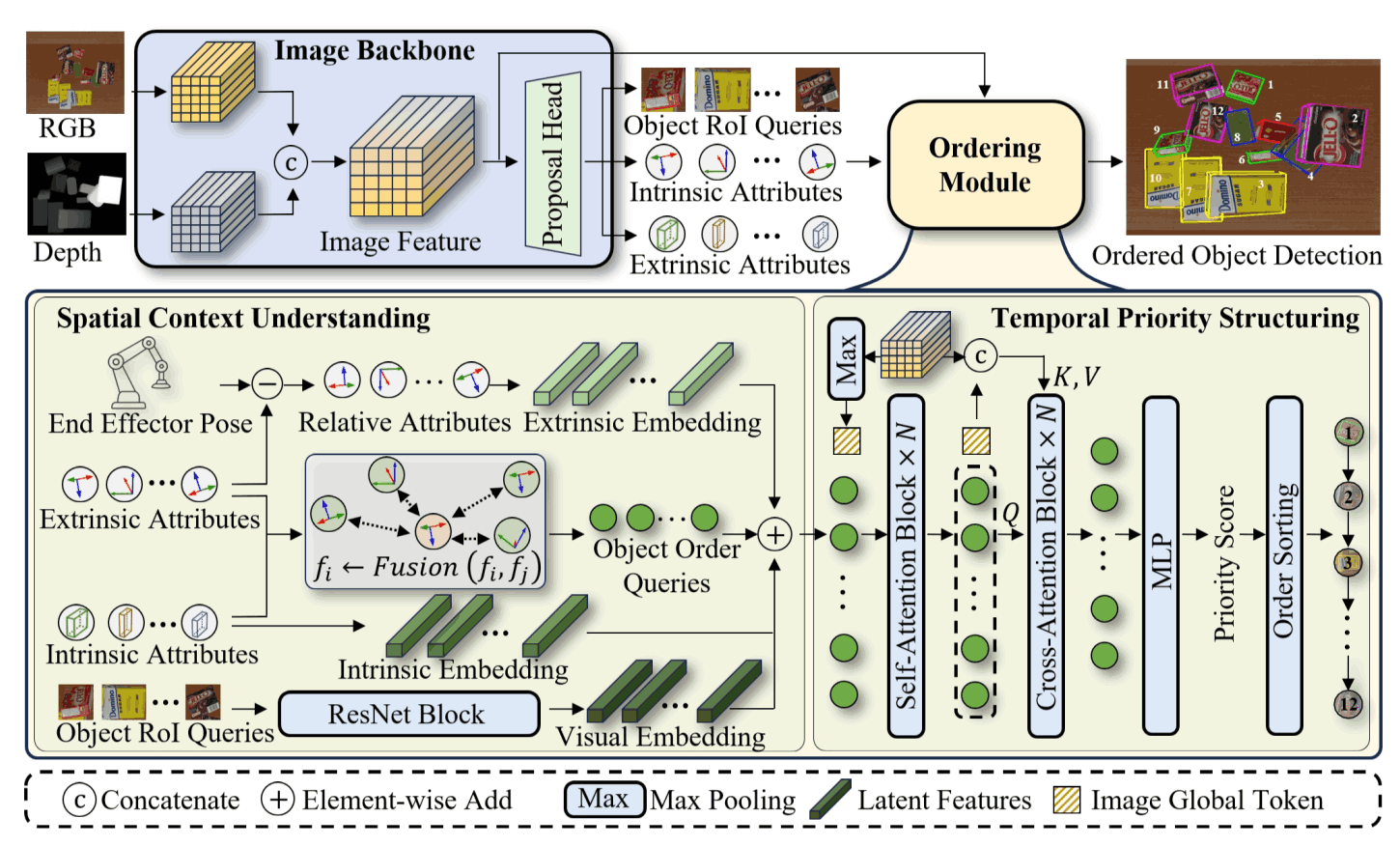
Learning Spatial-Aware Manipulation Ordering
Yuxiang Yan, Zhiyuan Zhou, Xin Gao, Guanghao Li, Shenglin Li, Jiaqi Chen, Qunyan Pu, Jian Pu
- OrderMind is a spatial-aware manipulation ordering framework that learns object priorities from local geometry via a kNN spatial graph and a lightweight module, supervised by VLM-distilled situational knowledge for robotic embodied tasks.
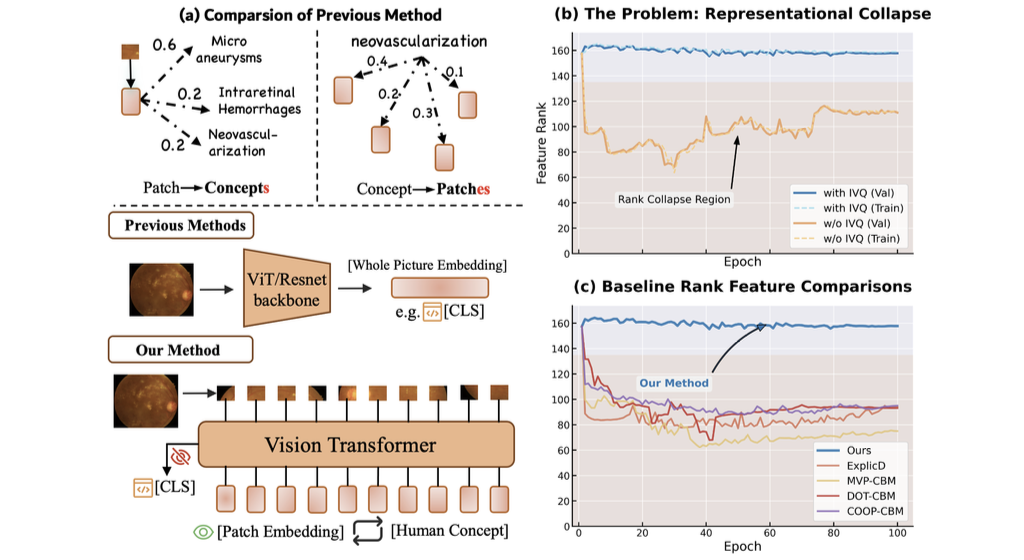
Escaping Low-Rank Traps: Interpretable Visual Concept Learning via Implicit Vector Quantization
Shujian Gao, Yuan Wang, Chenglong Ma, Xin Gao, Jiangtao Yan, Junzhi Ning, Cheng Tang, Changkai Ji, Huihui Xu, Wei Li, Ziyan Huang et al.
- IVQ acts as a structural regularizer to address representational collapse in Concept Bottleneck Models (CBMs). It anchors patch features to learned semantic prototypes continuously, preserving a high-rank, explainable representation space for visual concept learning.
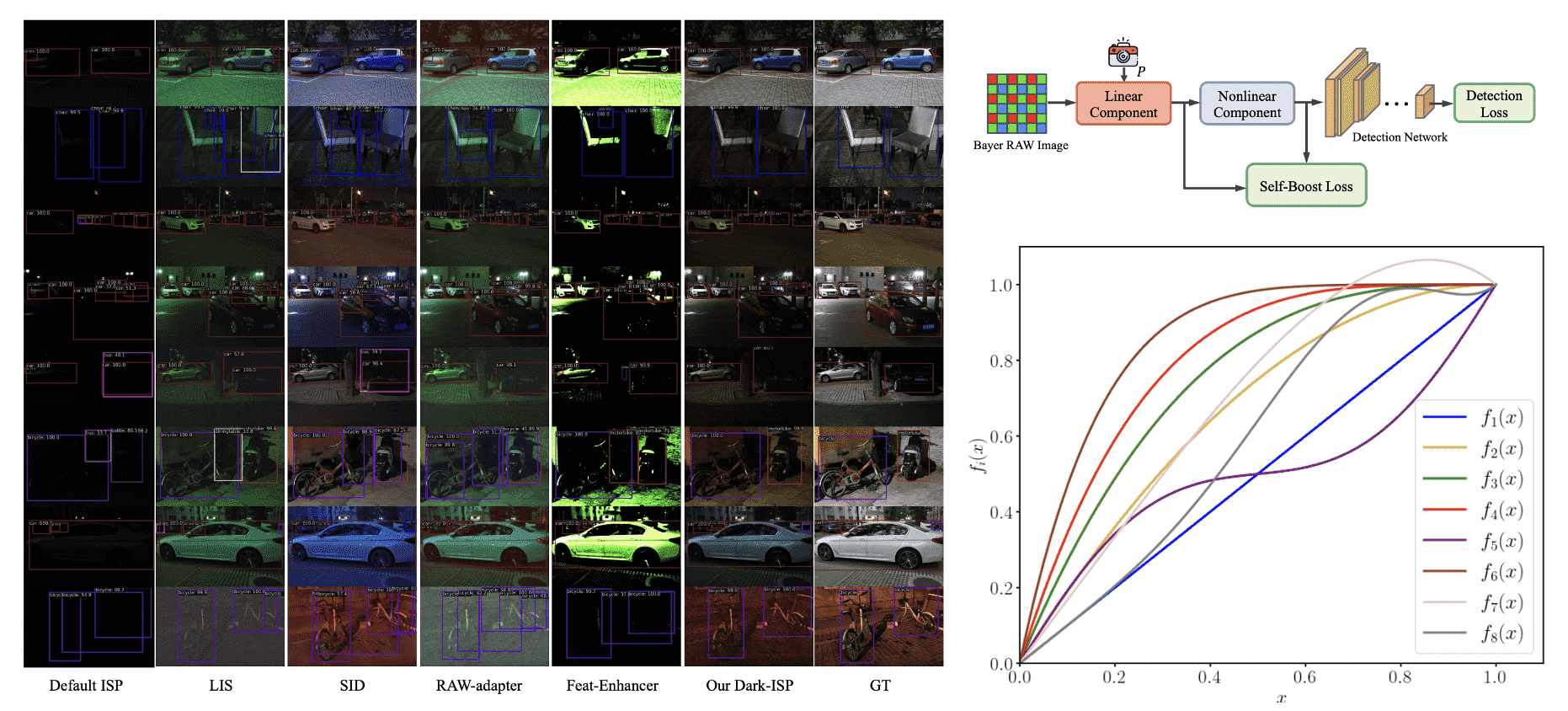
Dark-ISP: Enhancing RAW Image Processing for Low-Light Object Detection
Jiasheng Guo#, Xin Gao#, Yuxiang Yan, Guanghao Li, Jian Pu
- Dark-ISP is a lightweight, self-adaptive ISP plugin that enhances low-light object detection by processing Bayer RAW images. It breaks down traditional pipelines into optimized sub-modules, using physics-informed priors for robust sensory perception.
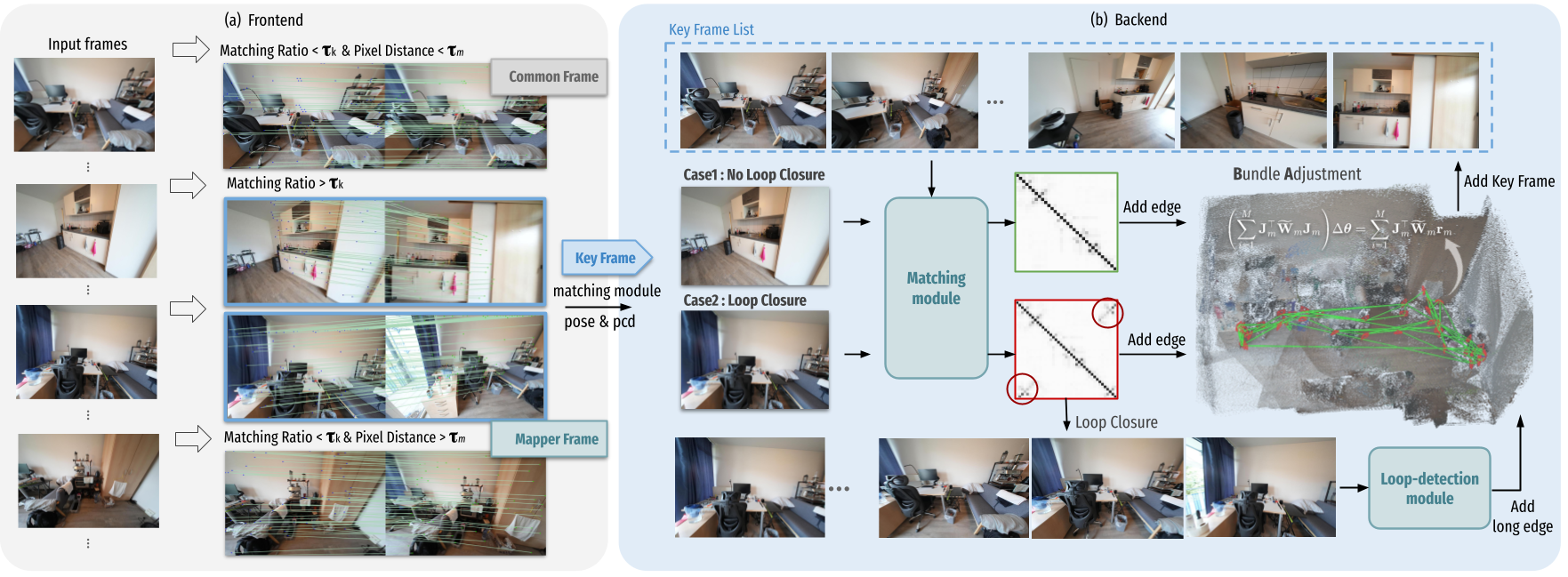
Guanghao Li, Kerui Ren, Linning Xu, Zhewen Zheng, Changjian Jiang, Xin Gao, Bo Dai, Jian Pu, Mulin Yu, Jiangmiao Pang


- ARTDECO unifies feed-forward 3D foundation priors with SLAM-style global optimization. It utilizes a hierarchical 3D Gaussian scene representation to achieve efficient, robust, and high-fidelity on-the-fly monocular 3D reconstruction.
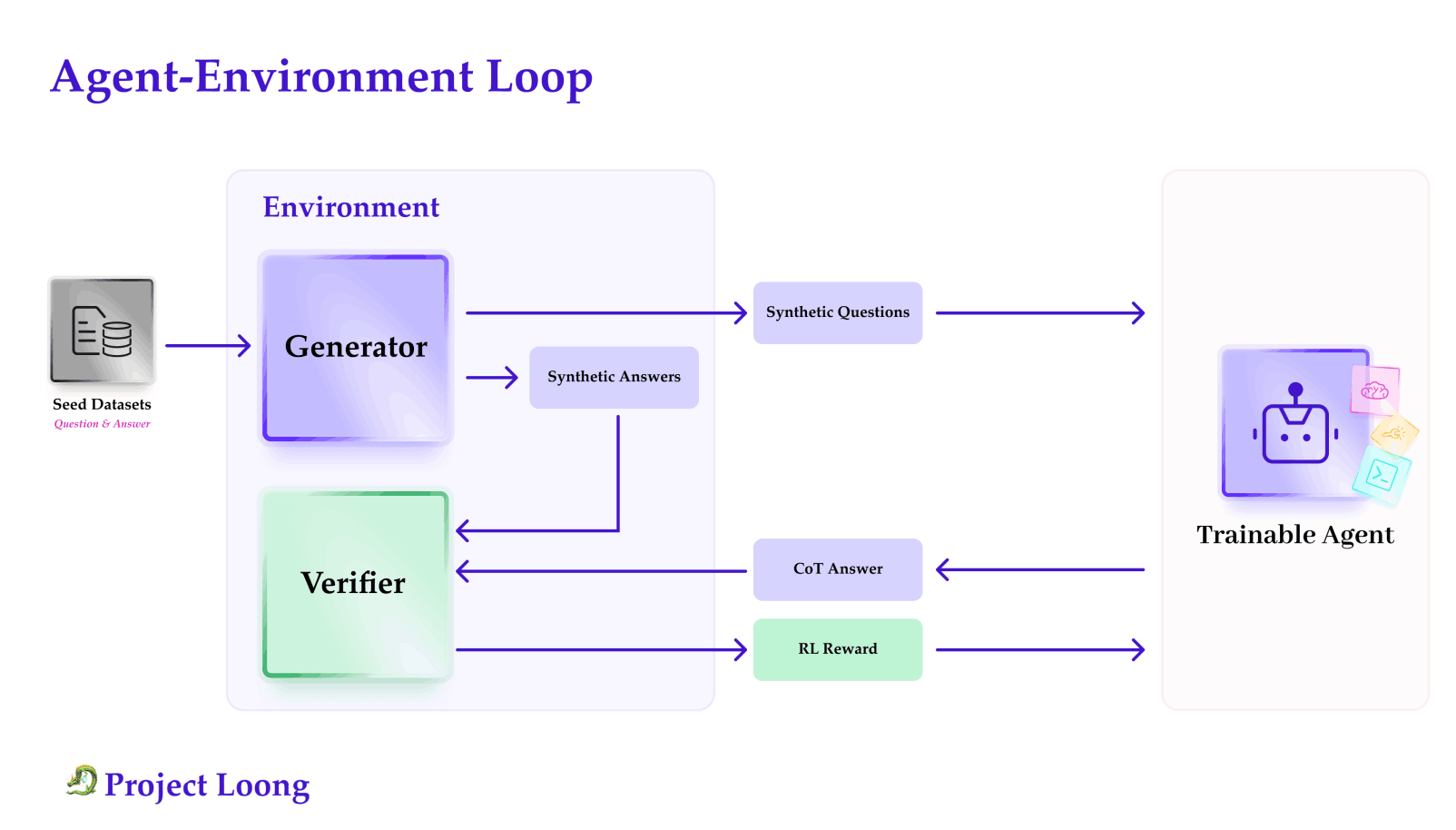
Loong: Synthesize Long Chain-of-Thoughts at Scale through Verifiers
Xingyue Huang, Rishabh, Gregor Franke, Ziyi Yang, Jiamu Bai, Weijie Bai, Jinhe Bi, Zifeng Ding, Yiqun Duan, Chengyu Fan, Wendong Fan, Xin Gao et al.


- Loong is an open-source framework for scalable, verifiable Chain-of-Thought (CoT) reasoning data generation. It pairs a large benchmark with a modular generator forming an agent–environment loop for broad-domain reasoning training and verification.
🎖 Honors and Awards
- 2023.09 Fudan University Zhicheng Freshman Second Prize Scholarship (Top 5%)
- 2023.06 Outstanding Graduate of Shanghai
- 2022.11 Second Prize in the Chinese Mathematics Competitions (Category A)
- 2021.12 National Scholarship, China
- 2021.09 National Second Prize in the China Undergraduate Mathematical Contest in Modeling
- 2020.12 Shanghai Scholarship
👨💼 Academic Service
- Conference Reviewer: NeurIPS 2025, ICCV 2025, ICLR 2026, ICML 2026 (Silver Reviewer), NeurIPS 2026
📖 Educations
- 2023.09 - 2026.06 (now), Master of Applied Mathematics, Fudan University, Shanghai, China.
- 2019.09 - 2023.06, Bachelor of Mathematics, Donghua Univeristy, Shanghai, China.
💻 Internships
- 2026.02 - present, Microsoft Research Asia, Beijing, China.
- 2025.05 - 2025.12, Shanghai AIlab, Shanghai, China.
📚 Learning Materials
😁 If you want the following material without watermarks, please contact me using the email address and specify your intended use.
Material 1: Frontiers in Diffusion Model Technologies (1)
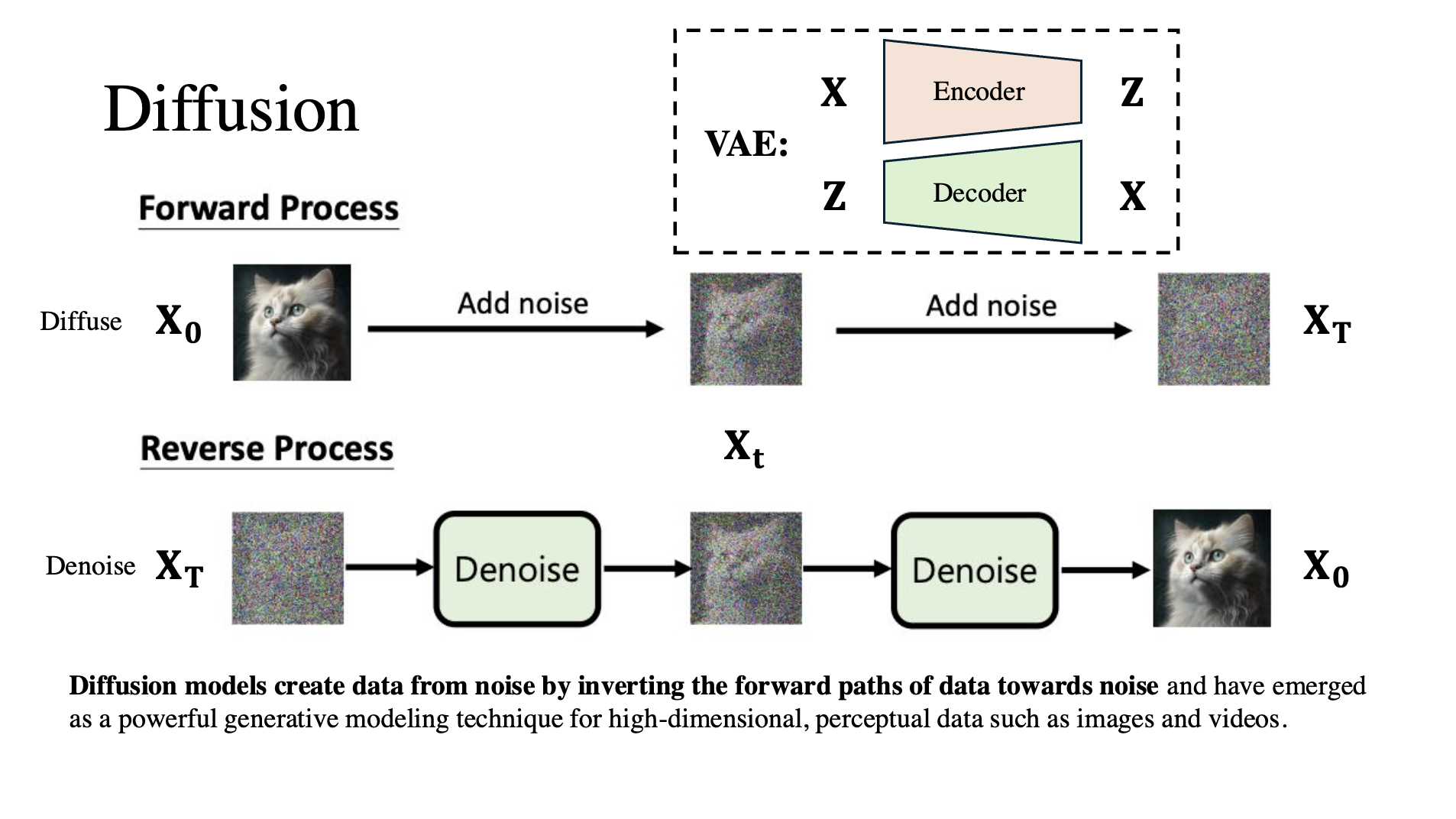
This document provides an overview of key concepts related to diffusion models, particularly focusing on the theoretical foundations, development timeline, and recent advancements in the field. The content includes detailed discussions on VAE, DDPM, DDIM, SDE, and ODE, as well as conditional guidance. It also covers the evolution of stable diffusion, including topics like Latent Diffusion, VQ-VAE, and DiT. Lastly, the document highlights the latest methodology, IC-Light, set to be presented at ICLR 2025.
Material 2: Tutorial of Information Geometry and t3-VAE
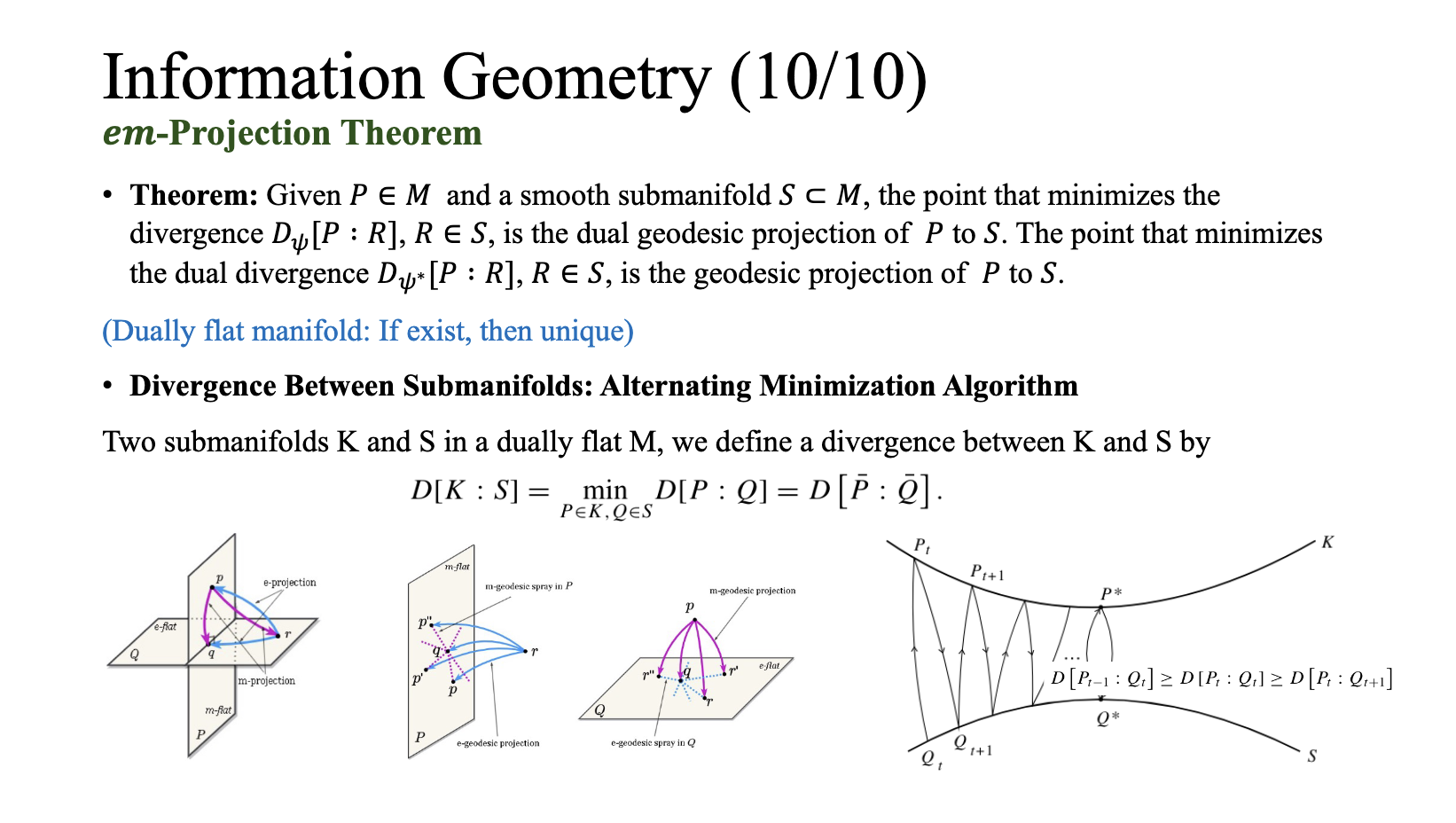
This document introduces the t3-Variational Autoencoder (ICLR 2024), which uses Student’s t-distributions to model heavy-tailed data distributions and improve latent variable representations. It also explores the framework of Information Geometry, focusing on how generative models can be understood through statistical manifolds, divergences, and Riemannian metrics, providing a deeper understanding of probability distributions and their applications in machine learning, signal processing, and neuroscience.
Material 3: EM Algorithm and X-metric

This document introduces the X-metric framework (PAMI 2023), an N-dimensional information-theoretic approach designed for groupwise registration and deep combined computing, with applications in advanced machine learning tasks. It also covers the theoretical foundations, including entropy, mutual information, and the MLE algorithm, alongside the framework’s modifications for deep computing and network training.